
データ拡散の測定:定義、リーチ、ストレージ
データ拡散の測定:定義、範囲、偏差、オーバーレイ、四分位数とそれらの式– データの広がりを測定する方法は?この機会に Knowledge.co.idについて データの広がりの大きさの公式とそれに関する他の事柄について議論します。 それをよりよく理解するために、以下の記事の議論を見てみましょう。
目次
-
データ拡散の測定:定義、範囲、偏差、オーバーレイ、四分位数とそれらの式
-
範囲または範囲または範囲
- データリーチ
- 四分位範囲
- 四分位偏差(半四分位範囲)
-
平均偏差
- 単一データ
- グループ化されたデータ(グループ)
-
バラエティまたはバリエーション
- 単一データのバリエーション
- クラスター化されたデータのバリエーション(クラスター化)
-
標準偏差
- 単一データの標準偏差
- グループ化されたデータの標準偏差
- オーバーレイ(H)または四分位範囲(JAK)
- 四分位数
- 問題の例
- これを共有:
- 関連記事:
-
範囲または範囲または範囲
データ拡散の測定:定義、範囲、偏差、オーバーレイ、四分位数とそれらの式
データスプレッドのサイズは、データが平均からどれだけ広がっているかを示す尺度です。 統計資料のデータの広がりの尺度には、範囲、オーバーレイ、および四分位数が含まれます。
範囲、オーバーレイ、および四分位数の意味は、次のとおりです。
- 範囲または範囲は、最大のデータ値と最小のデータ値の差です。
- 四分位範囲オーバーレイまたは範囲(JAK)は、上位四分位数(Q3)と下位四分位数(Q1)の差です。
- 四分位数は、順序付けられたデータの数をパーツごとに同じ数に分割することです。 各セクションは、下位四分位数(Q1)、中間四分位数(Q2)、および上位四分位数(Q1)を含む四分位値で区切られます。
この記事で調査するデータ拡散の測定値、つまり範囲、平均偏差、多様性(変動)、および標準偏差があります。
範囲または範囲または範囲
単一のデータで、最大値と最小値を簡単に知ることができます。 では、グループデータはどうですか? 範囲は、最大データと最小データの差です。 範囲は多くの場合Rで表されます。
また読む:液胞は次のとおりです:特性、機能、構造およびタイプ
データリーチ
R = xmax – xmin
情報:
R =範囲
Xmax =最大データ
Xmin =最小データ
データカバレッジの質問の例
データの範囲を決定します:3、6、10、5、8、9、6、4、7、5、6、9、5、2、4、7、8。
回答:
R = xmax – xmin
= 10-2 = 8
したがって、データの範囲は8です。
四分位範囲
四分位範囲は、3番目と1番目の四分位数の差です。
H = Q3 – Q1
情報 :
H =四分位範囲
Q3 = 3番目の四分位数
Q1 =最初の四分位数
四分位偏差(半四分位範囲)
四分位数の偏差は、3番目と1番目の四分位数の差の半分です。
Sk = Q3 – Q1
情報 :
Sk =四分位偏差
Q3 = 3番目の四分位数
Q1 =最初の四分位数

平均偏差
平均偏差は、各データと平均または計算された平均との差の平均値です。 平均偏差はしばしばSRで表されます。
単一データ
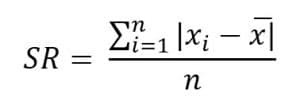
情報 :
SR =平均偏差
Xi = iデータ
X =算術平均
n =大量のデータ
グループ化されたデータ(グループ)
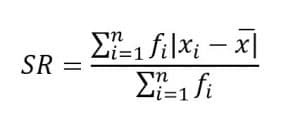
情報 :
SR =平均偏差
Xi = iデータ
X =算術平均
fi = i番目のデータ頻度
バラエティまたはバリエーション
多様性または変動は、データグループ内のデータの広がりの大きさを示す値です。 多様性または変動はs2で示されます。
単一データのバリエーション
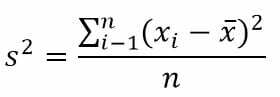
情報 :
s2 =バリエーション
xi =データから–i
x =算術平均
n =大量のデータ
クラスター化されたデータのバリエーション(クラスター化)
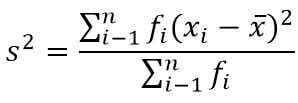
情報 :
s2 =バリエーション
xi =データから–i
x =算術平均
fi = i番目のデータ頻度
標準偏差
標準偏差または標準偏差とも呼ばれる値は、偏差の2乗の合計をデータ数で割った値の平方根です。 標準偏差はしばしばsで表されます。
単一データの標準偏差

情報 :
S =標準偏差
xi =データから–i
x =算術平均
n =大量のデータ
グループ化されたデータの標準偏差
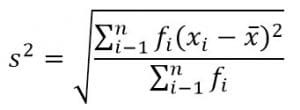
情報 :
s =標準偏差
xi =データから–i
x =算術平均
fi = i番目のデータ頻度
また読む:あなたが知る必要がある健康のためのレモンの利点
オーバーレイ(H)または四分位範囲(JAK)
データのオーバーレイ値は簡単に見つけることができます。
JAK = Q3-Q1
四分位数
- 四分位数は、順序付けられたデータセットを4つの等しい部分に分割するフラクタイルです。
- 四分位数のタイプは、下位四分位数またはQ1、中間四分位数またはQ2、および上位四分位数またはQ3です。
- データ型に基づく四分位グループ、つまり単一データ四分位数とグループデータ四分位数
以下は、四分位偏差、四分位平均、3四分位平均、および5つの系列統計を含む四分位データのレビューです。
- 四分位偏差またはしばしば半四分位範囲と呼ばれる値は、ストレッチの半分の時間を示す値です。 これは、上位四分位数から下位四分位数を減算し、2で割ることによって得られます(2)。
- 四分位数の平均は、上位四分位数と下位四分位数の平均です。 平均四分位数を取得する方法は、上位四分位数と下位四分位数を合計してから、2で除算することです。
- 3四分位平均は、上位四分位、中四分位、および下位四分位で構成される3つの四分位値の平均です。 四分位数の平均を取得する方法は、3つの四分位数を合計してから、2で割ることです。
- 統計は5つの値、つまりxmaxの最高値、xminの最低値、上位四分位(Q1)、中間四分位(Q2)、および下位四分位(Q3)で構成されるデータです。
問題の例
データの範囲を決定します:3、6、10、5、8、9、6、4、7、5、6、9、5、2、4、7、8。
回答:
R = xmax – xmin
= 10-2 = 8
したがって、データの範囲は8です。
それはからのレビューです Knowledge.co.idについて 約 データスプレッドサイズ, うまくいけば、それはあなたの洞察と知識に追加することができます。 ご覧いただきありがとうございます。他の記事もお読みください。